
真核生物的蛋白表达相对于原核宿主要复杂得多,其主要依赖于mRNA的5’帽子结构,但是对于后面的共表达蛋白,并没有这个结构,从而无法进行翻译。真核生物大多基因是单顺反子结构也印证了这一点。此时,需要一些有别于原核共表达元件的帮助,最常用的是下面两种:
/ IRES序列 /
IRES全名为内部核糖体进入位点,在一些病毒和部分真核基因结构中存在,它的存在能够使蛋白质翻译起始不依赖于5‘帽子结构,从而使直接从mRNA的中间起始翻译。将IRES构建到两个基因中间,这样第一个蛋白靠5’帽子结构起始翻译,而第二个蛋白则依靠IRES起始翻译。
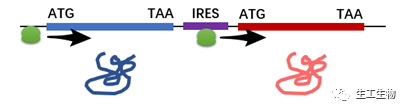
在很多真核共表达商业化质粒中,都出现过IRES的身影,举一个简单的例子,提问:以下两个真核质粒功能上的区别在哪里?
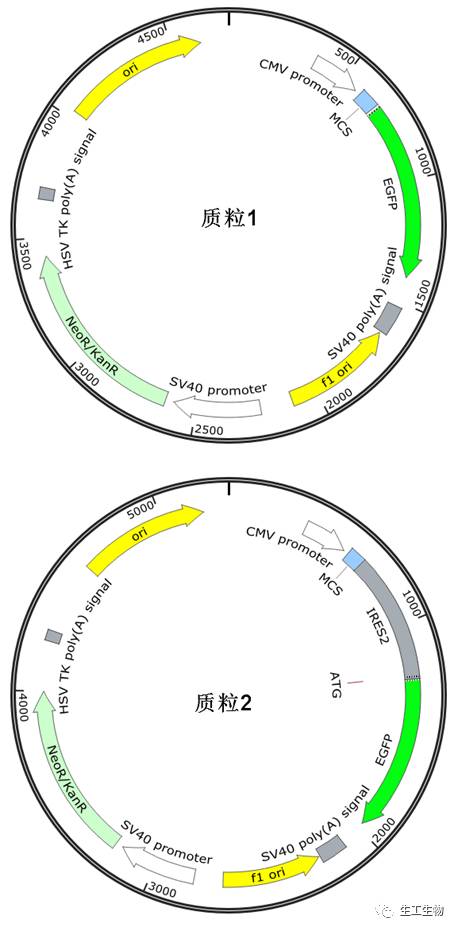
【答案】
区别在与egfp基因之前是否含有IRES序列,这直接导致了其功能上的不同,质粒1由于没有IRES,因此它主要用于目的基因与egfp的融合表达,可以用于对目的蛋白进行示踪。质粒2中的egfp基因前面含有IRES序列,使得插入的基因与egfp能够独立的进行表达,EGFP的作用主要是考察质粒的转染效率而不会对目的蛋白产生任何影响。
IRES的序列并不难查找,在NCBI以及诸多商业化质粒比如Clonetech的Bicistronic IRES系列质粒中都能查询到序列。
然而,IRES并不是全能的,它仍然存在诸多缺点:1. IRES的序列比较长(将近600bp),无法像原核SD序列一样通过引物扩增即可添加。2. 无法实现上下游两个蛋白的等量表达,通常情况下,下游蛋白的表达量仅为上游蛋白的10%~50%。
那么如何能够实现上下游蛋白的等量共表达呢?下面这个元件可以胜任:
/2A肽元件/
2A是仅存在与病毒中的一段基因元件,最早发现于口蹄疫病毒,大家都知道,病毒的基因组是非常小的,可谓寸土寸金,必须要找到一个最简约的方案来表达它需要的蛋白。于是,病毒进化出了2A,2A的肽段仅包含18~22个氨基酸,不同来源的2A在C端具有高度保守性,为-D-(V/I)-E-X-N-P-G-//-P。X为任意氨基酸,//为切割或跳跃位点。它能阻止翻译过程中氨基酸形成共价键,并维持翻译继续进行,发生的位置在倒数第二位Gly和最后一位Pro之间。这个过程被形象地称为“核糖体跳跃”(也有称为“顺式水解反应”),即核糖体从编码Gly的密码子跳跃至编码Pro的密码子而中间没有肽键形成,从而“断裂”为两个独立的蛋白。
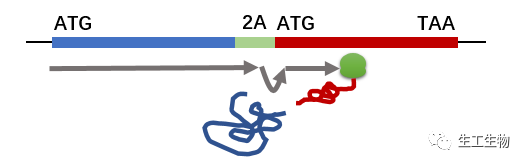
2A肽的剪切效率极高,昆虫病毒和猪捷申病毒中的2A切割效率几乎是100%,因此使用2A肽作为共表达元件,能够实现多蛋白的等量表达。2A肽的DNA序列也是很容易查到的,在一些商业化的真核共表达载体中能够查到,这些质粒的名称中通常有2A字样,一个典型的序列为EGRGSLLTCGDVEENPG*P(*为切割位点),其DNA序列为54bp,也是可以通过长引物PCR将其引入基因中的。以上是2A肽的两个最突出的优点。

在构建2A共表达模式时需要注意,务必需将上游基因的终止密码子去除掉,并保证下游基因与上游基因的阅读框通顺性,因为理论上来讲,2A共表达属于一种特殊的融合表达,只不过蛋白能够在2A肽处断裂罢了。
当然2A肽也是有一定缺点的,首先,由于独特的断裂模式,表达产物并非精确的两个蛋白序列,而是在上游蛋白的C端多了2A的氨基酸序列(除去最后一个),下游蛋白也会在N端多出一个脯氨酸。虽然多出的一个或几个氨基酸往往不会对蛋白的结构和功能产生影响,但运气背的时候你们都懂的……
本次推送就到这里啦,做共表达的小伙伴们可以参考一下~
觉得有用的请收藏~
觉得没用的请点赞~
小伙伴们再见~
